

La mauvaise qualité de données est le Mal qui ronge les campagnes de Marketing. Léonard vous montre dans cet article comment vaincre cette hydre à plusieurs têtes, lancer et réussir votre chantier Data Quality.
Les symptômes du Mal
Peut être êtes vous déjà convaincu que vous devriez vous occuper de la data quality, peut être pas. Quelques symptômes habituels que la Bête maléfique a investi votre Royaume.
Le mot intégration CRM vous fait vous réveiller la nuit
Vous ne comprenez pas comment cela marche, vous avez l’impression que certains champs sont échangés, d’autres non. Le même champ apparaît plusieurs fois dans votre Marketing Automation avec différents nom presque similaires (par exemple le champ Pays) et vous ne savez jamais lequel utiliser. Lorsque vous croisez le responsable CRM dans les couloirs, vous rasez les murs
Vos ciblages ne donnent jamais les résultats escomptés
A chaque fois que vous préparez un ciblage pour une campagne et estimez avoir X personnes, vous en avez moitié moins. Après un peu d’analyse, vous vous rendez compte que les champs sont
- soit vides car la donnée a été remplie dans un autre champ,
- soit elle a été remplie de manière erronée (UK au lieu de United Kingdom par exemple)
Et vous n’avez pas le temps de tout corriger à la main.
Vous n’avez aucune idée des consentements précis donnés par vos prospects et clients
Vous avez globalement une idée via ce champ, ah non, celui-ci, ou peut-être encore celui-ci si je le croise avec cette campagne… Mais difficile d’avoir une idée précise immédiate, fiable.
Vous recevez régulièrement des emails d’insultes
De la part d’hommes que vous avez appelé “Madame”. Ou de clients à qui vous avez proposé une offre pour les prospects, et qui découvrent la remise à laquelle ils n’ont pas eu droit en tant que client. Ou encore de la part de personnes qui vous ont dit 15 fois qu’ils ne voulaient plus être invités à vos webinars. Votre estime de vous-même est au plus bas.
Vos formulaires de lead gen sont longs et convertissent peu
Comme vous avez peu de données sur les personnes, vous en demandez beaucoup… et les prospects convertissent moins car personne n’aime les longs formulaires.
Vous refusez de mesurer le taux de doublons dans votre base pour garder votre santé mentale
C’est votre “pièce noire” où vous refusez d’entrer. Vous savez qu’elle est là, et qu’une horrible vérité se cache à l’intérieur… Mais parfois, mieux vaut ignorer la vérité, pour avoir l’illusion de vivre heureux. Bref, le tableau n’est pas rose, mais vous avez enfin décidé de l’affronter en face ! Nous allons ensemble défaire cette hydre à plusieurs têtes, et je vais vous montrer comment.
Préalable à votre chantier Data Quality : Comprendre le développement de l’Hydre, ou la dynamique de la mauvaise qualité de données
Il est important d’avoir en tête comment la mauvaise qualité naît, se propage et s’installe dans vos systèmes en vue de préparer votre chantier Data Quality. Nous vous avons préparé ce Miro pour vous aidez à y voir plus clair, soit en image, soit directement dans Miro.
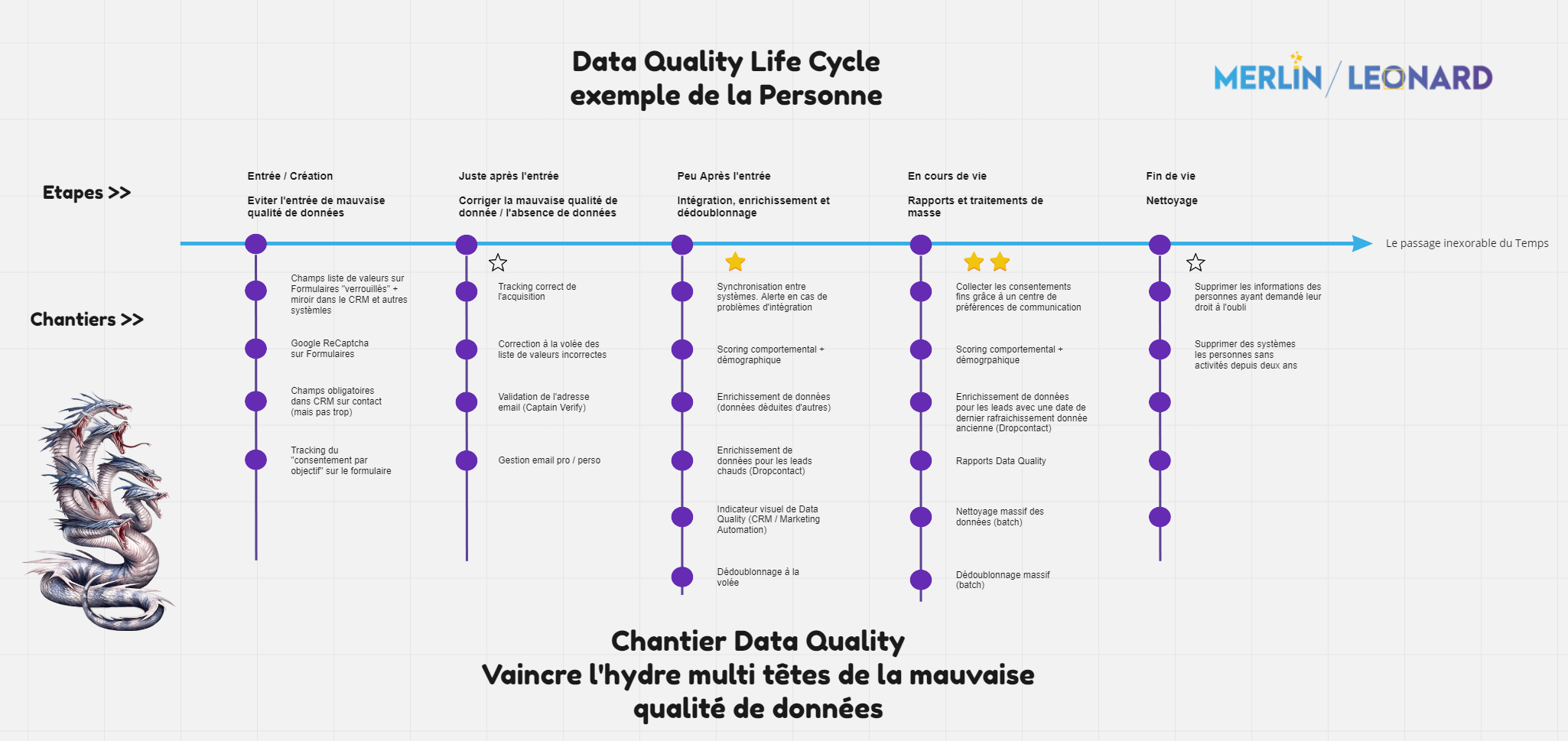
Pour traiter le sujet correctement et vaincre chacune des têtes de l’hydre, il est nécessaire de comprendre la dynamique de la Data Quality, qui est une matière vivante. Il vous faudra
- affronter les démons du passé (nettoyer la mauvaise qualité existante),
- revêtir votre armure la plus étincelante (éviter de faire entrer de la mauvaise qualité de donnée)
- et combattre le Mal dès son apparition (corriger à la volée).
Eviter de faire entrer le Mal
Pour vaincre les têtes de l’Hydre, rien de mieux que d’éviter de nourrir la Bête. Différentes techniques sont à votre disposition pour vaincre le Mal à la source.
Sécuriser vos formulaires
Les formulaires sont une grande source de mauvaise qualité, et en même temps, une grande source de génération de leads. Les actions que vous pouvez mettre en place pour limiter l’entrée de mauvaise qualité de données. Attention, cela ne doit pas se faire au détriment de l’expérience client. L’idée est de garder un formulaire le plus court possible pour maximiser la conversion.
- privilégier les listes de valeurs, au lieu de champs texte (par exemple pour les Pays)
- éviter de demander des données que vous pouvez avoir par ailleurs. La civilité qui peut être déduite à partir du prénom
- sécurisez vos formulaires avec un Google Recaptcha ou équivalent
- ne permettez pas l’entrée d’emails “perso” si vous êtes en B2B. Prévoyez un processus de traitement d’exception pour ceux qui n’ont pas d’autre emails à ce moment-là)
- évitez de demander des champs que vous pouvez déduire par ailleurs (civilité, niveau décisionnaire…). Vous voulez garder vos formulaires les plus courts possibles, ne demandez pas de l’information que vous pouvez avoir par ailleurs
- proposez une liste déroulante de sociétés à partir des premières lettres tapées par le visiteur dans votre champ « Société ». Ainsi vous sécurisez cette donnée cruciale pour le dédoublonnage
- trackez le consentement donné par le visiteur (cookie + consentement par objectif. Exemple : consentement pour les événements sur une formulaire d’inscription à un webinaire)

Sécurisez TOUTES vos sources de données
Ces propositions sont valables quel que soit la source d’entrée “externe”, c’est-à-dire partout où un visiteur peut s’authentifier pour la première fois : formulaire de marketing automation, webinaires ou événements, applis vidéo, réseaux sociaux, questionnaires et auto-évaluations… Par exemple chez Merlin/Leonard, cela va concerner nos formulaires Marketo, mais aussi Outgrow (quizz et assesments), TwentyThree (vidéo). Si l’un de ces systèmes ne peut assurer toutes les mesures préventives, il faut mettre en place des sécurités à l’entrée du CRM ou du Marketing Automation.
Sécurisez l’entrée de données dans le CRM
Le CRM est une autre source de qualité de données … approximative. Le Marketing, l’Administration des Ventes et la DSI se sont parfois ligués sans le savoir pour faire porter aux commerciaux le rôle de scribe. C’est une très mauvaise idée. Premièrement le temps des commerciaux vaut très cher, c’est dommage de leur demander de faire des tâches que pas mal de gens peuvent faire, souvent mieux qu’eux. Deuxièmement, ils ont – s’ils sont bons – une personnalité aux antipodes de celle nécessaire à la fonction de scribe. Dans l’ancien temps, je faisais des projets CRM. Il m’est arrivé de voir une page « Opportunité” avec 280 champs !

L’une des bonne pratique en matière de chantier de data quality est bizarrement de faire un audit du remplissage de votre CRM et de supprimer les champs massivement non remplis des pages contacts, leads, opportunités…. Quand vous y réfléchissez, pourquoi devrait-il y avoir plus de champs obligatoires dans votre CRM que dans un formulaire marketing ? Vous acceptez de procurer une bonne expérience client à votre visiteur en lui permettant de démarrer une relation avec vous avec peu de champs ; et de compléter son profil au fur et à mesure de son chemin avec vous. Pourquoi ne serait-ce pas pareil en interne avec les utilisateurs du CRM? Le travail que vous faites côté formulaires Marketing devrait aussi s’appliquer côté CRM :
- limiter le nombre de champs au maximum
- privilégier les champs calculés, déduits, enrichis à l’extérieur
- identifier clairement les champs à entrer manuellement, et ceux calculés automatiquement
- sécuriser vos champs importants avec des listes de valeurs contraintes
- grouper clairement les champs par thème (champs de contact, champs RGPD, champs “KPIs”, champs Data Quality…)
Combattre l’Hydre dès son apparition, ou corriger à la volée la mauvaise qualité de données
Il arrivera toujours qu’une tête de l’hydre arrive à passer vos meilleurs sorts. Parfois, elle arrive à corrompre vos propres troupes qui font un import de données catastrophiques et font entrer eux-mêmes le Mal au sein du Royaume. Comment traiter au plus vite le Mal une fois détecté ? Nous allons privilégier les campagnes en temps réel. Elles vont identifier les problèmes dès leur entrée, et apporter une solution immédiate.
Traquer correctement l’acquisition de données
Éternel combat que celui-ci ! Il s’agit de pouvoir répondre aux questions simples : d’où viennent mes leads ? D’où vient mon pipeline ? D’où vient mon revenu? Différents niveaux d’informations doivent être collectés :
- la source : webinaire, contenu “gated”, CRM…
- le détail de la source : par exemple pour la source “Webinaire”, on devrait avoir le nom du webinaire
- Quel canal de promotion a amené le visiteur (les fameux UTM : utm_source, utm_medium, utm_campagne)
- la date d’acquisition
Assez souvent, sans préparation, ces données sont au mieux absentes, au pire inconsistantes entre elles. Chaque source d’acquisition doit être surveillée, et ces informations doivent être remplies correctement dès l’entrée. Ci-dessous l’exemple d’un export simple des personnes en base avec le champ « Person Source ». Il reflète la raison qui les a amenées dans la base Marketing. On voit que pas mal de sources sont orthographiées différemment rendant impossible une prise de décision sans retraitement des résultats.

Vous souhaitez savoir où vous en êtes sur ce sujet? Suivez le guide.
Corriger à la volée les listes de valeurs erronées
Il est assez facile aujourd’hui avec les systèmes de marketing automation ou de CRM de créer des workflows qui détectent que telle valeur dans tel champ ne correspond pas au référentiel acceptable. Par exemple, un membre de l’équipe s’est laissé corrompre et importe un fichier de participants à un événement, mais se trompe sur les pays. On peut analyser et trouver 80% des mauvaises données pays entrées dans le passé. Par exemple pour United Kingdom, ce sera UK, U.K., Unit. King., Royaume-Uni, RU, R.U., Angleterre… Si l’on détecte qu’une personne est entrée avec l’une de ces mauvaises valeurs, alors remplacer immédiatement avec Royaume-Uni. Cela suppose de maîtriser ses champs et les valeurs acceptables. C’est généralement dans le Data Dictionary qu’on va référencer les « bonnes » valeurs pour chaque champ avec liste de valeurs.
Valider l’adresse email
Vous avez des systèmes tiers qui aujourd’hui peuvent vous valider une adresse email et vous éviter des envois futurs à des adresses soit :
- génériques : contact@toto.com
- “personnelles” : sylvain@gmail.com
- pièges : certaines adresses emails sont des pièges qui, si vous les utilisez, déclenchent une plainte à la CNIL. Il faut absolument les détecter et les éviter.
- invalides
- …
Ces systèmes vous permettent d’éviter d’envoyer un email reçu et d’avoir en retour des informations permettant de déterminer la qualité de l’email. Chez Merlin/Leonard, nous utilisons CaptainVerify, sur lequel j’avais fait un Marketo tip.
Ci-dessous les données renvoyées par CaptainVerify. Comme vous pouvez le voir, c’est assez riche et très utile pour le marketing.

Gestion Email Pro / Perso
Le fait d’utiliser une solution comme CaptainVerify amène assez vite à avoir plusieurs champs “email personnel” à côté du champ standard “Email”. On va essayer de le garder pour l’email professionnel. L’idée est la suivante :
- vous recevez un nouvel email
- Vous l’analysez – avec CaptainVerify ou en regardant si le domaine appartient à l’un des domaines d’emails personnels comme Gmail.
- Si non, pas de souci, rien à faire
- Si oui, vous le copiez dans le champ “Email personnel”. Vous essayez alors de récupérer l’email professionnel via une solution comme DropContact.io.
- Ainsi vous aurez email pro et perso. Ce qui peut être utilie lorsque le contact change d’entreprise et que vous recevez un “Bounce” indiquant que l’email pro n’est plus valide.
- Vous pouvez alors lui écrire sur l’email perso pour lui demander sa nouvelle adresse perso via la centre de préférences de communications

Dédoublonner à la volée
C’est une fonctionnalité aujourd’hui assez basique heureusement. Côté Marketing Automation, votre clé de réconciliation sera l’email. Toute personne qui entre en base via un formulaire ou une liste d’import sera normalement reconnue si elle existe déjà en base avec le même email. Ce qui vous permet d’enrichir la connaissance client que vous avez de cette personne au fur et à mesure. Côté CRM, c’est plus compliqué car :
- l’email ne peut pas servir de clé assez souvent, car il existe des entreprises où plusieurs personnes utilisent le même emails et il faut pouvoir les entrer dans le CRM.
- il faut alors imaginer une “clé” fonctionnelle qui servira d’identifiant unique lorsque vous entrez des personnes : par exemple Nom + Prénom + Entreprise.
Si vous entrez un deuxième Sylvain Davril de M/L, le système vous demandera alors si ce ne serait pas le même que le premier.

Ce système n’est pas idéal car il peut fatalement exister des homonymes qui portent le même nom dans la même entreprise; D’autre part ces tests vont aussi s’appliquer à tout ce que le marketing automation va pousser dans la base. Et parfois rejeter l’entrée de leads chauds du fait d’une similitude. Donc à mettre en place si vous avez résolu le sujet de la remontée d’informations dans l’intégration. Des systèmes experts existent pour aller plus loin et dédoublonner sur la base de similitudes, j’en parle plus bas.
Prendre des mesures de fond pour éviter que l’Hydre de la mauvaise qualité de données ne s’installe
Nous sommes à l’orée de l’antre de la Bête; elle a réussi à faire son nid au sein du Royaume. Vous pouvez agir avant qu’elle ne s’installe durablement.
Synchronisation entre systèmes
Un sujet souvent occulté mais qui est une grande source de mauvaise qualité de données.
>> C’était mieux avant
Il fut un temps où les projets d’intégration comprenaient un volet “Remontée et traitement des erreurs”.
- Des “logs” d’information étaient produits à chaque échange d’information pour savoir si les données avaient été échangées correctement,
- Des alertes étaient envoyées aux responsables de systèmes IT et métiers pour prendre les mesures adéquates
- Et des mesures auto correctrices étaient parfois mises en place pour rejouer le jeu de données défectueux à un moment ultérieur
>> La data quality des intégrations aujourd’hui
Aujourd’hui, lorsqu’on reçoit une alerte que quelque chose s’est mal passé, on s’estime heureux ! Donc en cas de problème de transmission de données, au mieux, un message abscons va être envoyé. La personne qui le reçoit ne saura pas le lire “car c’est trop technique”. Et de toutes façons n’en aura pas le temps ni l’envie car il y a ce fichu webinaire à envoyer ! Résultat, vous pouvez voir des interfaces qui ne fonctionnent pas bien pendant plusieurs jours / semaines sans que cela inquiète personne. Et des données qui se désynchronisent entre systèmes.
>> Exemple qui va vous parler :
- une personne remplit votre centre de préférences et demande à exercer son droit à l’oubli
- vous traitez le sujet côté Marketing
- un problème d’intégration empêche l’échange de données avec votre CRM (par exemple, parce le champ Pays est vide)
- un commercial envoie à cette personne un email d’invitation à votre prochain webinaire
- et c’est le drame, vous êtes convoqué au juridique, et personne n’aime être convoqué au juridique
Donc demandez à votre DSI de mettre en place ces alertes, avec des messages compréhensibles lorsque un échange de données échoue, afin que vous puissiez agir tout de suite.

Identifier facilement l’hydre
Un des moyens de combattre l’Hydre est de mobiliser tout le monde. Encore faut-il pour cela que chacun reconnaisse le Mal au premier coup d’oeil. C’est l’objet de l’indicateur visuel de Data Quality : généralement un score de couleur, ou une pastille vert / jaune / rouge sur la fiche contact. Cela permet de voir tout de suite si une action est requise ou pas. L’indicateur pourra être calculé en fonction de différentes données sur la fiche d’un contact :
- complétude des champs : les champs essentiels au contact sont-ils bien remplis ? Le nombre de champs nécessaires peut évoluer en fonction de l’avancée de la personne dans le cycle de vie.
- exactitude des champs : les champs sont-ils remplis avec des données correctes (par exemple l’email est il valide? le numéro de téléphone ressemble-il à un vrai numéro? Les valeurs des champs liste de valeur sont-elles correctes?)
- fraicheur des données : les données sont-elles récentes?
Déduire des données à partir d’autres
Toujours dans l’esprit de réduire les demandes de saisie de données soit pour les visiteurs, soit pour les ventes, vous pouvez aujourd’hui automatiser la déduction de données.
Exemple 1 : la Civilité
Par exemple la Civilité peut être déduite en partie à partir des prénoms.
- Si Prénom = Marie ou Claire ou … alors la civilité est « Mme »
- Si Prénom = Jeau ou Paul ou … alors la civilité est « M. »
Il existe des liste de prénoms dont la civilité est « sûre » par pays. Il est alors assez facile de créer ce type de campagne de Data Quality transverse.
Exemple 2 : le niveau décisionnaire
Idem, à partir du « poste », on peut assez souvent déduire le niveau décisionnaire.
- si poste contient Directeur, DG, CEO, Partner… alors niveau décisionnaire est « Décideur »
- Si poste contient étudiant, Consultant, journaliste, indépendant, freelance, alors niveau décisionnaire est « Autre »
- Sinon niveau décisionnaire est « Management intermédiaire »
Et ainsi de suite par exemple pour le Service de la personne encore une fois à partir du Poste.

Enrichissement de données
Un niveau au-dessus, l’enrichissement de données nécessite de faire appel à une base tierce. A vous de décider quand vous faites un appel à cette base pour enrichir la donnée :
- à la création du contact dans votre base, ce qui permet d’avoir des enregistrements « propres » en entrée ; et derrière continuer les autres processus de Data Quality par exemple le dédoublonnage ; cette méthode risque néanmoins d’engendrer de nombreux appels
- à un certain moment du parcours client, par exemple, juste avant de le passer aux ventes. Cela réduit le nombre d’appels et le coût. Et cela intervient à un moment crucial, en permettant de réduire le travail de qualification de l’équipe des Ventes.
Nous utilisons Dropcontact.io chez Merlin/Leonard. Voici le type de données que nous pouvons récupérer à partir d’un nom, prénom et d’un email

Les données d’enrichissement de Dropcontact.io
Plusieurs façons de faire existent pour intégrer cette donnée dans votre base : Vous pouvez écraser directement les champs existants avec la data importée. Ou vous pouvez créer des champs dédiés pour stocker la data importée, et des champs sauvegardes pour garder une trace de la donnée que vous allez écraser. Vous sauvegardez la donnée avant de l’écraser.
L’Hydre est là : monter une équipe pour débouter le monstre de sa tanière
Centre de préférences de communications
Nous avons pas mal de littérature sur le centre de préférences et la RGPD. Sans centre de préférences, pas de collecte des consentements fins de vos visiteurs , et donc pas d’expérience client réussie. Vos clients veulent peut-être être informés de vos événements et de vos documents d’expertise, mais ne veulent pas lire votre newsletter ni vos promotions produits. Je rencontre assez souvent des clients qui n’ont pas vraiment géré le sujet « Consentements » – enfin de moins en moins -, et où la documentation est inexistante. On trouve des mélanges de champs « opt-out » – je veux être exclu – et « opt-in » – je veux être inclus – au niveau global – inclure / exclure de tout- et local – inclure/exclure de la newsletter par exemple -. Lorsque l’on commence à analyser la donnée, on trouve des personnes avec des consentements opt-in sur la newsletter par exemple qui sont aussi exclues opt-out au niveau global. Le résultat est qu’il leur est difficile de savoir comment inclure ou exclure les personnes en base lorsqu’ils créent une campagne. Et ceci engendre des plaintes de clients qui ont demandé à être exclus et qui continuent de recevoir des communications, Ou à l’inverse, des personnes qui ont demandé à être incluses mais que vous ne touchez pas. Ce n’est pas possible. Il faut qu’en fonction des campagnes, le consentement à choisir soit évident. Placez vous en plus à la place de la personne qui n’a pas conçu les champs à choisir, qui hésite, qui a peur de faire une bourde… La solution est de mettre en place un centre de préférences, où l’ensemble de ces règles de gestion sont correctement gérées.
Enrichissement régulier des données
15% de la base change de poste en moyenne chaque année. C’est bien d’enrichir les données à l’entrée, c’est encore mieux de prévoir ceci régulièrement. Comment faire? Avec les systèmes de marketing automation modernes, rien de plus simple. Par exemple vous pouvez mettre en place une règle disant que vous allez faire un appel à la base d’enrichissement tierce :
- dès que la personne voit son score comportemental changer (cela signifie qu’elle est active)
- mais limiter les appels à un tous les 6 mois ou un an
KPIs et Rapports Data Quality
C’est généralement un gain de temps considérable lorsque vous avez vos jeux de rapports et Dashboards prêts à l’emploi. Vous pouvez vous les envoyer toutes les semaines pour gardez un oeil sur l’état de la base. En vérité, cela n’existe quasiment jamais 😉 C’est un effort à faire au fur et à mesure que vous allez entreprendre vos différents chantiers Data Quality. Le pack idéal de rapports Data Quality contient selon moi – côté CRM et / ou Marketing automation – les donnés permettant de répondre aux questions ci-dessous :
- Acquisition de données : les source sont-elles correctes? les sources sont-elles cohérentes avec les campagnes sources? Toutes les personnes ont-elles une source et une campagne d’acquisition?…
- Centre de préférences : les données de consentements sont-elles correctes ? (si vous avez mis des listes de valeurs Oui/Non, n’existe-t-il que ces deux valeurs et « NULL »?). Les consentements locaux et globaux sont-ils cohérents ? (personne en optout global et optin = Yes sur la newsletter). Les dates de changement de consentement sont-elles bien tracées?
- Listes de valeurs : les champs listes de valeurs ne contiennent-ils que des valeurs acceptables?
- Scoring / Lead Life cycle : toutes les personnes ont-elles un statut correspondant à leur place dans le Lead Life Cycle? Les statuts et le score sont-ils cohérents? Certaines personnes sont-elles bloquées sur un statut depuis une durée suspecte?
Ces rapports doivent vous permettre d’identifier rapidement les problème, et la source du Mal. A vous de corriger derière. Un petit exemple d’une série de Smart Lists Marketo orientées Data Quality autour du Lead Life Cycle

Dédoublonnage massif
Nous parlons ici d’identifier et de solutionner les types de situations suivantes :
- identifier + corriger que deux personnes avec le même email et des noms légèrement différents sont identiques :
- Sylvain Davril sylvain.davril@merlinleonard.com
- et Silvain D’avril sylvain.davril@merlinleonard.com
- identifier + corriger que deux personnes avec des attributs identiques mais des emails différents sont identiques :
- Sylvain Davril sylvain.davril@merlinleonard.com
- Sylvain Davril sylvain.davril@gmail.com
- identifier que deux personnes (ou plusieurs) avec des attributs et emails légèrement différents sont identiques
- Sylvain Davril de Merlin/Leonard
- Silvain D’aville de Merlin
Les systèmes experts type Cloudingo peuvent calculer un score de similitude basé sur des chaine de caractères – ici prénom+nom+société -. Et vous dire si la chaîne est « semblable » ou pas (pour les techy, c’est basé sur le score de Jaro-Winkler) A vous derrière de décider de fusionner ou pas, manuellement ou automatiquement.
Généralement, on fait une première passe de dédoublonnage massif lorsqu’on installe la solution; puis on opère par détection au fil de l’eau au fur et à mesure que les contacts entrent en base.


